Gaussian-Linear Hidden Markov Model#
This notebook shows an example of training and inspecting a Gaussian-Linear Hidden Markov Model (GLHMM). This model is fit to two sets of timeseries, such as a neuroimaging/electrophysiological recording and a corresponding behavioural or other physiological timeseries. If you want to model just one set of timeseries, you can e.g., use the Standard Gaussian HMM. If you are new to the HMM or the GLHMM toolbox, we recommend starting there for a thorough introduction.
Outline#
Example: Modelling time-varying interaction between brain and physiological data
Initialise and train a GLHMM
-
Interaction between brain and physiological measures
State means and covariances
Dynamics: Transition probabilities and Viterbi path
Background#
The GLHMM is a generalization of the HMM, introduced in Vidaurre et al., 2023. We here assume that the observations Y at time point t were generated by a Gaussian distribution with parameters \(\mu\) and \(\Sigma\) (similar to the standard Gaussian HMM), as well as regression coefficients \(\beta\) that relate the second set of variables X to Y. When state k is active at time point t, the GLHMM thus assumes that the timeseries Y follows the following distribution:
Compared to the standard Gaussian HMM, the GLHMM thus adds the \(X_t\beta^k\) term, which allows modelling the relationship to a second set of variables.
The remaining HMM parameters are essentially the same as in the standard HMM, i.e. the transition probabilities \(\theta\):
the initial state probabilities \(\pi\):
as well as the posterior estimates for both X and Y:
The GLHMM can be used to model, in addition to the patterns described by the standard HMM (such as time-varying amplitude or functional connectivity), temporal changes in the relationship between two timeseries. This could be, for instance, the interaction between one group of brain areas in the prefrontal cortex and another group of brain areas in the occipital cortex, the relationship between BOLD-signal across the whole brain and respiration, or the interaction between EEG recordings from two participants recorded simultaneously.
Example: Modelling time-varying interaction between brain and physiological data#
We will now go through an example illustrating how to fit and inspect a GLHMM. The example uses simulated data that can be found in the example_data folder. The data were generated to resemble one set of fMRI timeseries and two corresponding non-brain physiological (e.g., heart rate and respiration) timeseries. Our goal is to estimate time-varying amplitude and functional connectivity (FC) within the fMRI recordings and temporal changes in the relationship between the fMRI and the
physiological data.
Preparation#
If you have not done so, install the glhmm repo using:
[ ]:
pip install glhmm
We then need to import the relevant modules:
[1]:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
from glhmm import glhmm, preproc, utils
Load data#
The GLHMM requires two inputs: a timeseries Yand a second timeseries X. When running the model on a concatenated timeseries, e.g., a group of subjects or several scanning sessions, you also need to provide the indices indicating where each subject/session in the concatenated timeseries Y starts and ends. Loading data and data formats are explained in more detail in the Standard Gaussian HMM tutorial.
Synthetic data for this example are provided in the glhmm/docs/notebooks/example_data folder. The file data.csv contains synthetic data for the first set of timeseries Y. This is the brain data, containing fMRI recordings from 20 subjects with 1,000 timepoints each, concatenated along the first dimension, and 50 brain areas. The file dataX.csv contains the corresponding physiological measures, heart rate and respiration. The sessions have the same duration as the brain data,
i.e., there are 20 concatenated subjects with 1,000 timepoints each, but only 2 variables (heart rate and respiration). The file T.csv specifies the beginning and end of each subject’s session (same for X and Y).
[2]:
data_tmp = pd.read_csv('./example_data/data.csv', header=None)
dataX_tmp = pd.read_csv('./example_data/dataX.csv', header=None)
T_t_tmp = pd.read_csv('./example_data/T.csv', header=None)
brain_data = data_tmp.to_numpy()
phys_data = dataX_tmp.to_numpy()
T_t = T_t_tmp.to_numpy()
del data_tmp, dataX_tmp, T_t_tmp
NOTE: It is important to standardise your timeseries and, if necessary, apply other kinds of preprocessing before fitting the model. This will be done separately for each session/subject as specified in the indices. The data provided here are already close to standardised (so the code below will not do much), but see Prediction tutorial to see the effect on real data.
[3]:
brain_data,_ = preproc.preprocess_data(brain_data, T_t)
phys_data,_ = preproc.preprocess_data(phys_data, T_t)
Initialise and train a GLHMM#
We first initialise the glhmm object, which we here call brainphys_glhmm. By specifying the parameters of the glhmm object, we define which type of model we want to fit and how states should be defined. In the case of the GLHMM, we need to set the model_beta parameter to indicate that we wish to model an interaction between two sets of variables. There are two options for modelling the interaction: global, meaning we estimate regression coefficients that are static over the timeseries in
which case model_beta='shared', or state-dependent, meaning we estimate regression coefficients that vary over time in which case model_beta='state'. In this example, we want to model the time-varying interaction between the brain data and the physiological data, so we set model_beta='state'. For the other parameters, we here want to use the same set-up as in the standard Gaussian HMM, i.e., each state will be defined in terms of mean and covariance.
That means, we will also estimate the time-varying amplitude and functional connectivity in the brain timeseries. We model 4 states by setting the parameter K=4, which you can compare to the states from the standard Gaussian HMM.
[4]:
brainphys_glhmm = glhmm.glhmm(model_beta='state', K=4, covtype='full')
We can check the hyperparameters of the object to make sure the model is defined as we planned:
[5]:
print(brainphys_glhmm.hyperparameters)
{'K': 4, 'covtype': 'full', 'model_mean': 'state', 'model_beta': 'state', 'dirichlet_diag': 10, 'connectivity': None, 'Pstructure': array([[ True, True, True, True],
[ True, True, True, True],
[ True, True, True, True],
[ True, True, True, True]]), 'Pistructure': array([ True, True, True, True])}
We then train the model. To model the interaction, we need to train the GLHMM using both the brain data and the physiological data. The “main” timeseries we are looking to model, i.e., the data for which we also want to estimate mean and covariance, is Y, so in this case Y=brain_data. The secondary timeseries from which we model only the interaction with the main timeseries is called X so X=phys_data. When fitting the model to a group of subjects or sessions, we also need to
specify the indices of the start and end of each session (here called T_t). Note that the indices are shared for X and Y, so the beginning and end of the sessions in X and Y need to correspond.
[ ]:
brainphys_glhmm.train(X=phys_data, Y=brain_data, indices=T_t)
Inspect model#
Interaction between brain and physiological measures#
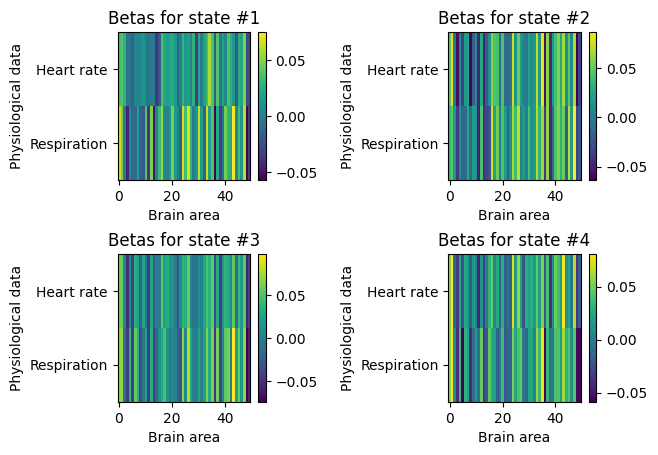
Let’s start by retrieving the parameters describing the interaction, i.e., the \(\beta\) values, between the two sets of timeseries: the brain data and the physiological data (heart rate & respiration). The beta-values can be obtained from the trained model using the get_betas() function (or alternatively get_beta(k) to obtain only the beta-values for state k):
[9]:
K = brainphys_glhmm.hyperparameters["K"] # the number of states
q = brain_data.shape[1] # the number of parcels/channels
state_betas = np.zeros(shape=(2,q,K))
state_betas = brainphys_glhmm.get_betas()
Since we here defined \(\beta\) to be time-varying, i.e., state-dependent, we have a matrix describing the interaction between each of the 50 brain regions and the 2 physiological measures for each of the 4 states:
[10]:
for k in range(K):
plt.subplot(2,2,k+1)
plt.imshow(state_betas[:,:,k], aspect='auto', interpolation='none')
plt.colorbar()
plt.ylabel('Physiological data')
plt.yticks(np.arange(2), ["Heart rate", "Respiration"])
plt.xlabel('Brain area')
plt.title("Betas for state #%s" % (k+1))
plt.subplots_adjust(hspace=0.5, wspace=1)
plt.show()
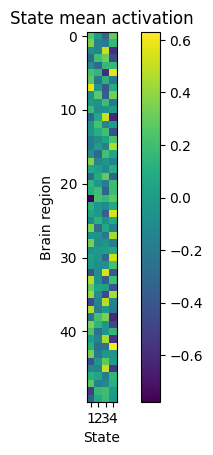
State means and covariances#
We have defined the model so that each state also has a mean (amplitude) and covariance (functional connectivity), as in the Standard Gaussian HMM. We can retrieve them by using the get_mean and get_covariance_matrix functions:
[11]:
state_means = np.zeros(shape=(q, K))
for k in range(K):
state_means[:,k] = brainphys_glhmm.get_mean(k) # the state means in the shape (no. features, no. states)
state_FC = np.zeros(shape=(q, q, K))
for k in range(K):
state_FC[:,:,k] = brainphys_glhmm.get_covariance_matrix(k=k) # the state covariance matrices in the shape (no. features, no. features, no. states)
And plot them:
[12]:
plt.imshow(state_means, interpolation="none")
plt.colorbar()
plt.title("State mean activation")
plt.xticks(np.arange(4), np.arange(1,5))
plt.gca().set_xlabel('State')
plt.gca().set_ylabel('Brain region')
plt.show()
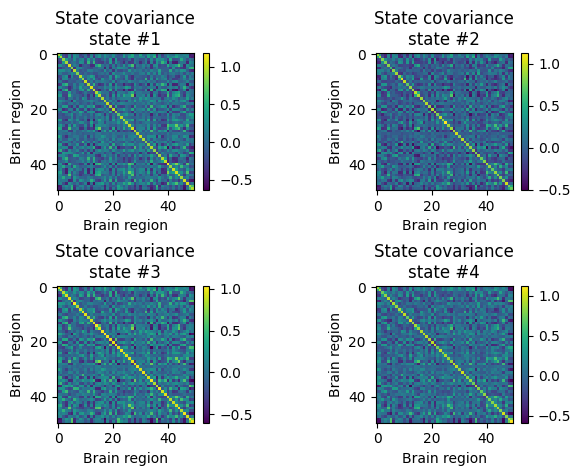
[15]:
for k in range(4):
plt.subplot(2,2,k+1)
plt.imshow(state_FC[:,:,k], interpolation="none")
plt.xlabel('Brain region')
plt.ylabel('Brain region')
plt.colorbar()
plt.title("State covariance\nstate #%s" % (k+1))
plt.subplots_adjust(hspace=0.7, wspace=0.8)
plt.show()
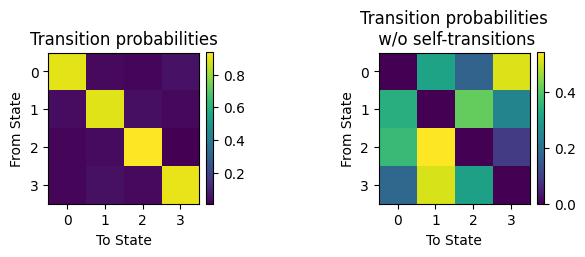
Dynamics: Transition probabilities and Viterbi path#
We can also look at the transition probabilities and the Viterbi path to understand the temporal sequence in which the states occur. See Standard Gaussian HMM for a detailed explanation. The transition probabilities with and without self-transitions:
[16]:
TP = np.zeros(shape=(K, K))
TP = brainphys_glhmm.P.copy() # the transition probability matrix
plt.subplot(1,2,1)
plt.imshow(TP)
plt.xticks(np.arange(4))
plt.yticks(np.arange(4))
plt.title('Transition probabilities')
plt.xlabel('To State')
plt.ylabel('From State')
plt.colorbar(fraction=0.046, pad=0.04)
plt.subplot(1,2,2)
TP_noself = TP.copy()
np.fill_diagonal(TP_noself, 0)
sumtmp = TP_noself.sum(axis=1)
TP_noself2 = TP_noself.copy()
TP_noself2 = (TP_noself.T / sumtmp[None,:]).T
plt.imshow(TP_noself2)
plt.xticks(np.arange(4))
plt.yticks(np.arange(4))
plt.title('Transition probabilities\n w/o self-transitions')
plt.xlabel('To State')
plt.ylabel('From State')
plt.colorbar(fraction=0.046, pad=0.04)
plt.subplots_adjust(wspace=1)
plt.show()
And the Viterbi path:
[18]:
vpath = brainphys_glhmm.decode(X=phys_data, Y=brain_data, indices=T_t, viterbi=True)
[19]:
signal =[]
xlabel = "Time"
figsize=(7, 4)
ylabel = ""
yticks=None
line_width=2
label_signal="Signal"
num_states = vpath.shape[1]
# Create a Seaborn color palette
colors = sb.color_palette("Set3", n_colors=num_states)
# Plot the stack plot using Seaborn
fig, axes = plt.subplots(figsize=figsize) # Adjust the figure size for better readability
axes.stackplot(np.arange(vpath.shape[0]), vpath.T, colors=colors, labels=[f'State {i + 1}' for i in range(num_states)])
# Set labels and legend to the right of the figure
axes.set_xlabel(xlabel)
axes.set_ylabel(ylabel)
axes.legend(title='States', loc='upper left', bbox_to_anchor=(1, 1)) # Adjusted legend position
# Remove y-axis tick labels
axes.set_yticks([])
# Remove the frame around the plot
axes.spines['top'].set_visible(False)
axes.spines['right'].set_visible(False)
axes.spines['bottom'].set_visible(False)
axes.spines['left'].set_visible(False)
axes.legend(loc='upper left', bbox_to_anchor=(1, 0.8)) # Adjusted legend position
# Increase tick label font size
axes.tick_params(axis='both')
plt.title('Viterbi path')
plt.tight_layout()
# Show the plot
plt.show()
As for the standard HMM, there is a range of useful summary metrics that you can compute to describe the obtained patterns. Have a look at the Standard Gaussian HMM tutorial to see how to obtain them from your trained model. These can be used, e.g., for statistical testing (see Statistical testing tutorial) or prediction/machine learning (see Prediction tutorial).