Standard Gaussian Hidden Markov Model#
This notebook goes through the basic steps to train and inspect a standard Gaussian Hidden Markov Model (HMM). This model is fit to a single set of timeseries, such as neuroimaging or electrophysiological recordings. If you want to model two sets of timeseries and their interaction, the toolbox also offers the Gaussian-Linear HMM.
Outline#
Example: Modelling time-varying amplitude and functional connectivity in fMRI recordings
Initialise and train an HMM
-
State means: Time-varying amplitude patterns
State covariances: Time-varying functional connectivity
Background#
The HMM is a generative probabilistic model that assumes that an observed timeseries (e.g., neuroimaging or electrophysiological recordings) were generated by a sequence of hidden “states”. In the Gaussian HMM, we model states as Gaussian distributions, so we assume that the observations Y at time point t were generated by a Gaussian distribution with parameters \(\mu\) and \(\Sigma\) when state k is active, i.e.:
Additionally, the HMM estimates the probabilities \(\theta\) of transitioning between each pair of states, i.e., the probability that the currently active state at time point t is k given that the state at the previous timepoint t-1 was l:
And the probability \(\pi\) that a segment of the timeseries starts with state k:
When we fit the model to the observations, we aim to estimate the parameters of the prior distributions for these parameters (\(\mu\), \(\Sigma\), \(\theta\), and \(\pi\)) using variational inference.
We define the posterior estimates as
where \(\gamma\) are the probabilities of state k being active at time point t (the state time courses) and \(\xi\) are the joint state probabilities. Instead of the state time courses, we can also use the Viterbi path, a discrete representation of which state is active at each time point.
A common application for the standard Gaussian HMM is the estimation of time-varying amplitude and functional connectivity in fMRI recordings (e.g., Vidaurre et al., 2017).
Example: Modelling time-varying amplitude and functional connectivity in fMRI recordings#
We will now go through an example illustrating how to fit and inspect a standard Gaussian HMM. The example uses simulated data that can be found in the example_data folder. The data were generated to resemble fMRI timeseries, and our goal is to estimate time-varying amplitude and functional connectivity (FC) for a group of subjects. Imagine that the data were recorded from 20 different subjects. Each subject has been recorded for 1,000 timepoints and their timeseries were extracted in a
parcellation with 50 brain regions. The data Y here thus has dimensions ((20 subjects * 1000 timepoints), 50 brain regions). We use the indices array to specify where in the timeseries each of the 20 subjects’ session starts and ends.
Preparation#
If you have not done so, install the repo using:
[ ]:
pip install glhmm
We then need to import the relevant modules:
[1]:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
from glhmm import glhmm, preproc, utils
Load data#
The standard HMM requires only one input: a timeseries Y. When running the model on a concatenated timeseries, e.g., a group of subjects or several scanning sessions, you also need to provide the indices indicating where each subject/session in the concatenated timeseries Y starts and ends.
Input data for the glhmm should be in numpy format. Other data types, such as .csv, can be converted to numpy using e.g. pandas, as shown below. Alternatively, the io module provides useful functions to load input data in the required format, e.g., from existing .mat-files. If you need to create indices from session lengths (as used in the HMM-MAR toolbox) you can use the auxiliary.make_indices_from_T function.
Synthetic data for this example are provided in the glhmm/docs/notebooks/example_data folder. The file data.csv contains synthetic timeseries. The data should have the shape ((no subjects/sessions * no timepoints), no features), meaning that all subjects and/or sessions have been concatenated along the first dimension. The second dimension is the number of features, e.g., the number of parcels or channels. The file T.csv specifies the indices in the concatenated timeseries
corresponding to the beginning and end of individual subjects/sessions in the shape (no subjects, 2). In this case, we have generated timeseries for 20 subjects and 50 features. Each subject has 1,000 timepoints. The timeseries has the shape (20000, 50) and the indices have the shape (20, 2).
[2]:
data_tmp = pd.read_csv('./example_data/data.csv', header=None)
T_t_tmp = pd.read_csv('./example_data/T.csv', header=None)
data = data_tmp.to_numpy()
T_t = T_t_tmp.to_numpy()
del data_tmp, T_t_tmp
NOTE: It is important to standardise your timeseries and, if necessary, apply other kinds of preprocessing before fitting the model. This will be done separately for each session/subject as specified in the indices. The data provided here are already close to standardised (so the code below will not do much), but see Prediction tutorial to see the effect on real data.
[3]:
data,_ = preproc.preprocess_data(data, T_t)
Initialise and train an HMM#
We first initialise the glhmm object and specify hyperparameters. In the case of the standard Gaussian HMM, since we do not want to model an interaction between two sets of variables, we set model_beta='no'. The number of states is specified using the K parameter. We here estimate K=4 states. If you want to model a different number of states, change K to a different value. In this example, we want to model states as Gaussian distributions with a mean and full covariance matrix, so
that each state is described by a mean amplitude and functional connectivity pattern. To do this, specify covtype='full', the state-specific mean is already set by default. If you do not want to model the mean, add model_mean='no'.
[4]:
hmm = glhmm.glhmm(model_beta='no', K=4, covtype='full')
Optionally, you can check the hyperparameters (including the ones set by default) to make sure that they correspond to how you want the model to be set up.
[5]:
print(hmm.hyperparameters)
{'K': 4, 'covtype': 'full', 'model_mean': 'state', 'model_beta': 'no', 'dirichlet_diag': 10, 'connectivity': None, 'Pstructure': array([[ True, True, True, True],
[ True, True, True, True],
[ True, True, True, True],
[ True, True, True, True]]), 'Pistructure': array([ True, True, True, True])}
We then train the HMM using the data and indices loaded above. Since we here do not model an interaction between two sets of timeseries but run a standard HMM instead, we set X=None. Y should be the timeseries in which we want to estimate states (in here called data) and indices should be the beginning and end indices of each subject (here called T_t). During training, the output will show the progress in model fit at each iteration.
[ ]:
hmm.train(X=None, Y=data, indices=T_t)
Optionally, you can also return Gamma (the state probabilities at each timepoint), Xi (the joint probabilities of past and future states conditioned on the data) and FE (the free energy of each iteration) at this step, but it is also possible to retrieve them later using the decode function for Gamma and Xi and the get_fe function for the free energy.
[ ]:
Gamma,Xi,FE = hmm.train(X=None, Y=data, indices=T_t)
Inspect model#
We can then inspect some interesting aspects of the model. We start by checking what the states look like by interrogating the the state means and the state covariances. We will then look at the dynamics, i.e., how states transition between each other (transition probabilities) and how the state sequence develops over time (the Viterbi path). Finally, we will have a look at some summary metrics that can be useful to describe the overall patterns or to relate the model to behaviour using statistical testing or machine learning/out-of-sample prediction. > We here show some simple result plots. For more plotting options, see the Graphics module
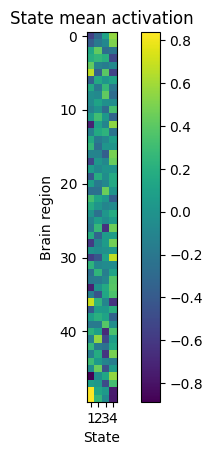
State means: Time-varying amplitude patterns#
The state means can be interpreted as time-varying patterns of amplitude (relative to the baseline). They can be retrieved from the model using the get_means() function, or get_mean(k) to retrieve only the mean for state k:
[64]:
K = hmm.hyperparameters["K"] # the number of states
q = data.shape[1] # the number of parcels/channels
state_means = np.zeros(shape=(q, K))
state_means = hmm.get_means() # the state means in the shape (no. features, no. states)
We can then plot these amplitude patterns. This will show the states on the x-axis, each parcel/brain region/channel on the y-axis, and the mean activation of each parcel in each state as the color intensity.
[55]:
plt.imshow(state_means, interpolation="none")
plt.colorbar()
plt.title("State mean activation")
plt.xticks(np.arange(4), np.arange(1,5))
plt.gca().set_xlabel('State')
plt.gca().set_ylabel('Brain region')
plt.show()
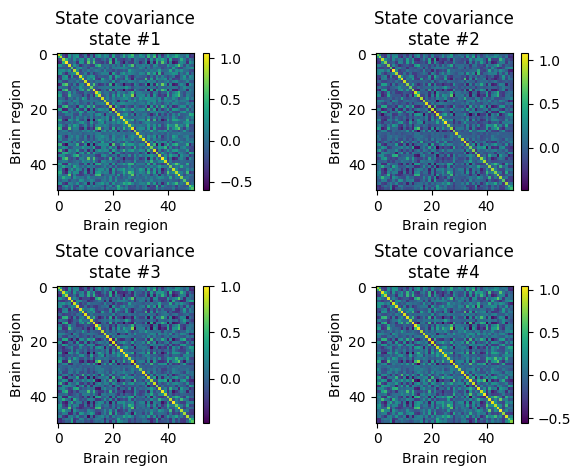
State covariances: Time-varying functional connectivity#
The state covariances represent the time-varying functional connectivity patterns that we have estimated in the fMRI recordings. They can be obtained from the model using the get_covariance_matrix function:
[63]:
state_FC = np.zeros(shape=(q, q, K))
for k in range(K):
state_FC[:,:,k] = hmm.get_covariance_matrix(k=k) # the state covariance matrices in the shape (no. features, no. features, no. states)
We can then plot the covariance (i.e., functional connectivity) of each state. These are square matrices showing the brain region by brain region functional connectivity patterns:
[61]:
for k in range(4):
plt.subplot(2,2,k+1)
plt.imshow(state_FC[:,:,k], interpolation="none")
plt.xlabel('Brain region')
plt.ylabel('Brain region')
plt.colorbar()
plt.title("State covariance\nstate #%s" % (k+1))
plt.subplots_adjust(hspace=0.7, wspace=0.8)
plt.show()
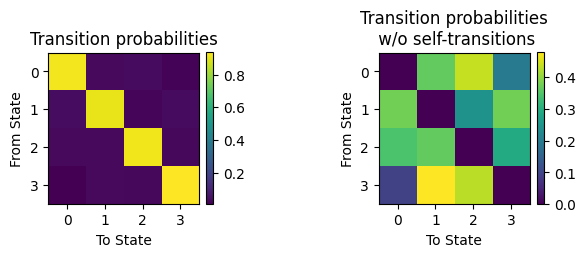
Transition probabilities#
The transition probabilities indicate the temporal order in the state sequence, i.e., the probability of transitioning from any one state to any other state. They are contained in hmm.P:
[8]:
TP = np.zeros(shape=(K, K))
TP = hmm.P.copy() # the transition probability matrix
We can then plot the transition probability matrix. Note that self-transitions (i.e., staying in the same state) are considerably more likely in a timeseries that has some order, so there should be a strong diagonal pattern. For comparison, we also show the transition probabilities excluding self-transitions:
[50]:
plt.subplot(1,2,1)
plt.imshow(TP)
plt.xticks(np.arange(4))
plt.yticks(np.arange(4))
plt.title('Transition probabilities')
plt.xlabel('To State')
plt.ylabel('From State')
plt.colorbar(fraction=0.046, pad=0.04)
plt.subplot(1,2,2)
TP_noself = TP.copy()
np.fill_diagonal(TP_noself, 0)
sumtmp = TP_noself.sum(axis=1)
TP_noself2 = TP_noself.copy()
TP_noself2 = (TP_noself.T / sumtmp[None,:]).T
plt.imshow(TP_noself2)
plt.xticks(np.arange(4))
plt.yticks(np.arange(4))
plt.title('Transition probabilities\n w/o self-transitions')
plt.xlabel('To State')
plt.ylabel('From State')
plt.colorbar(fraction=0.046, pad=0.04)
plt.subplots_adjust(wspace=1)
plt.show()
Viterbi path#
The Viterbi path is a discrete representation of the state timecourse, indicating which state is active at which timepoint. We may be able to see whether some states tend to occur more for certain subjects, or are related to a stimulus that occurs at specific timepoints. The Viterbi path can also be informative to understand whether the HMM is “mixing”, i.e., states occur across subjects, or whether the model estimates the entire session of one subject as one state (see Ahrends et al.
2022). You can retrieve the Viterbi path using the decode function and setting viterbi=True:
[12]:
vpath = hmm.decode(X=None, Y=data, indices=T_t, viterbi=True)
And plot the Viterbi path (see also graphics module):
[60]:
signal =[]
xlabel = "Time"
figsize=(7, 4)
ylabel = ""
yticks=None
line_width=2
label_signal="Signal"
num_states = vpath.shape[1]
# Create a Seaborn color palette
colors = sb.color_palette("Set3", n_colors=num_states)
# Plot the stack plot using Seaborn
fig, axes = plt.subplots(figsize=figsize) # Adjust the figure size for better readability
axes.stackplot(np.arange(vpath.shape[0]), vpath.T, colors=colors, labels=[f'State {i + 1}' for i in range(num_states)])
# Set labels and legend to the right of the figure
axes.set_xlabel(xlabel)
axes.set_ylabel(ylabel)
axes.legend(title='States', loc='upper left', bbox_to_anchor=(1, 1)) # Adjusted legend position
# Remove y-axis tick labels
axes.set_yticks([])
# Remove the frame around the plot
axes.spines['top'].set_visible(False)
axes.spines['right'].set_visible(False)
axes.spines['bottom'].set_visible(False)
axes.spines['left'].set_visible(False)
axes.legend(loc='upper left', bbox_to_anchor=(1, 0.8)) # Adjusted legend position
# Increase tick label font size
axes.tick_params(axis='both')
plt.title('Viterbi path')
plt.tight_layout()
# Show the plot
plt.show()
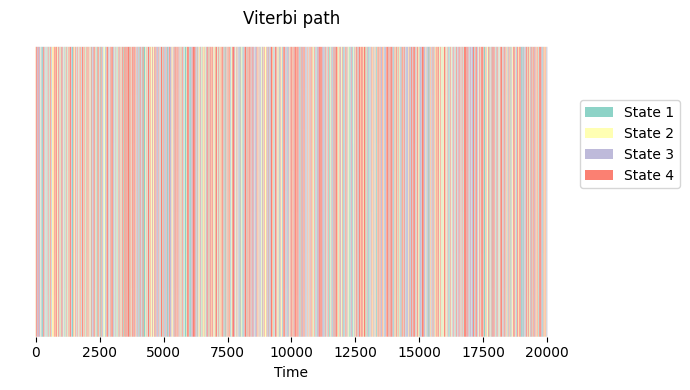
Plotting the Viterbi path indicates that the states show fast dynamics across all subjects (concatenated along the y-axis).
Summary metrics#
Once we have estimated the model parameters, we can compute some summary metrics to describe the patterns we see more broadly. These summary metrics can be useful to relate patterns in the timeseries to behaviour, using e.g., statistical testing (see Statistical testing tutorial) or machine learning (see Prediction tutorial). The module utils provides useful functions to obtain these summary metrics.
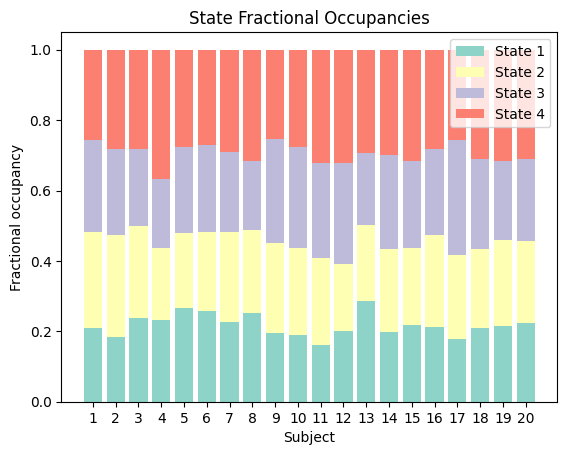
The fractional occupancy (FO) indicates the fraction of time in each session that is occupied by each state. For instance, if one state was active for the entire duration of the session, this state’s FO would be 1 (100%) and all others would be 0. If, on the other hand, all states are present for an equal amount of timepoints in total, the FO of all states would be 1/K (the number of states). This can be informative to understand whether one state is more present in a certain group of subjects or experimental condition, or to interrogate mixing (explained above).
You can obtain the fractional occupancies using the get_FO function. The output is an array containing the FO of each subject along the first dimension and each state along the second dimension.
[21]:
FO = utils.get_FO(Gamma, indices=T_t)
[43]:
fig, ax = plt.subplots()
bottom = np.zeros(20)
sessions = np.arange(1,21)
width = 0.5
for k in range(K):
p = ax.bar(sessions, FO[:,k], bottom=bottom, color=colors[k])
bottom += FO[:,k]
plt.xticks(sessions)
plt.xlabel('Subject')
plt.ylabel('Fractional occupancy')
plt.legend(['State 1', 'State 2', 'State 3', 'State 4'])
plt.title('State Fractional Occupancies')
plt.show()
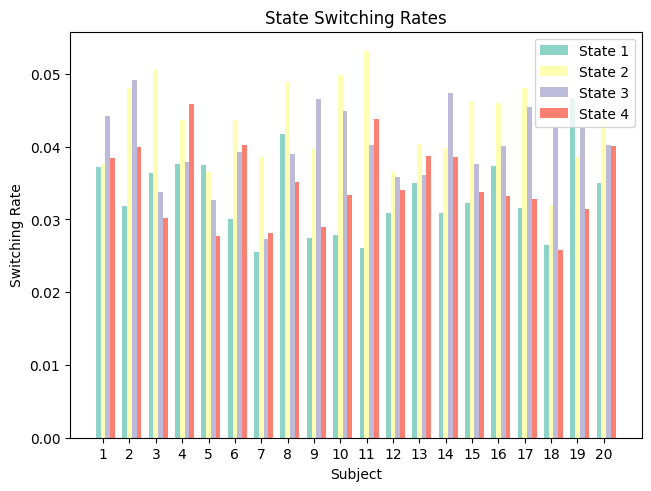
The switching rate indicates how quickly subjects switch between states (as opposed to stay in the same state).
[38]:
SR = utils.get_switching_rate(Gamma, T_t)
[44]:
fig, ax = plt.subplots(layout='constrained')
width = 0.18
multiplier = 0
for k in np. arange(K):
offset = width * multiplier
rects = ax.bar(sessions + offset, SR[:,k], width, color=colors[k])
multiplier += 1
ax.set_xticks(sessions + width, sessions)
plt.xlabel('Subject')
plt.ylabel('Switching Rate')
plt.legend(['State 1', 'State 2', 'State 3', 'State 4'])
plt.title('State Switching Rates')
plt.show()
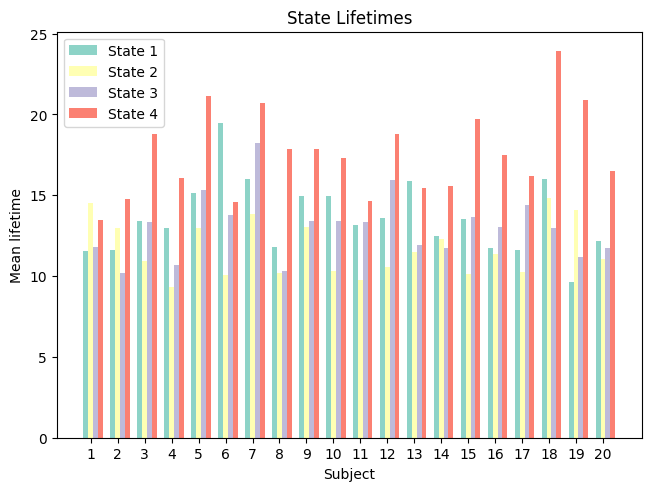
The state lifetimes (also called dwell times) indicate how long a state is active at a time (either on average, median, or maximum). This can be informative to understand whether states tend to last longer or shorter times, pointing towards slower vs. faster dynamics:
[45]:
LTmean, LTmed, LTmax = utils.get_life_times(vpath, T_t)
[46]:
fig, ax = plt.subplots(layout='constrained')
width = 0.18
multiplier = 0
for k in np. arange(K):
offset = width * multiplier
rects = ax.bar(sessions + offset, LTmean[:,k], width, color=colors[k])
multiplier += 1
ax.set_xticks(sessions + width, sessions)
plt.xlabel('Subject')
plt.ylabel('Mean lifetime')
plt.legend(['State 1', 'State 2', 'State 3', 'State 4'])
plt.title('State Lifetimes')
plt.show()